Example
This example demonstrates the whole process from initial atomic structure to training, evaluation and prediction. It includes:
Read input atomic structures (saved as extxyz files) and create descriptors and their derivatives.
Read inputs and outputs into a Data object.
Create tensorflow dataset for training.
Train the potential and apply it for prediction.
Save the trained model and then load it for retraining or prediction.
The code has been tested on Tensorflow 2.5 and 2.6.
[1]:
import atomdnn
# 'float64' is used for reading data and train by default
atomdnn.data_type = 'float64'
# force and stress are evaluated by default,
# if one only need to compute potential energy, then set compute_force to false
atomdnn.compute_force = True
# default value is for converting ev/A^3 to GPa
# note that: the predicted positive stress means tension and negative stress means compression
stress_unit_convert = 160.2176
import numpy as np
import pickle
import tensorflow as tf
from atomdnn import data
from atomdnn.data import Data
from atomdnn.data import *
from atomdnn.io import *
from atomdnn import network
from atomdnn.network import Network
Create descriptors
Read input atomic structures (saved as extxyz files) and create descriptors and their derivatives
[2]:
descriptor = {'name': 'acsf',
'cutoff': 6.5,
'etaG2':[0.01,0.05,0.1,0.5,1,5,10],
'etaG4': [0.01],
'zeta': [0.08,0.2,1.0,5.0,10.0,50.0,100.0],
'lambda': [1.0, -1.0]}
# define lammps excutable (serial or mpi)
# LAMMPS has to be compiled with the added compute and dump_local subrutines (inside atomdnn/lammps)
lmpexe = 'lmp_serial'
[3]:
xyzfile_path = './extxyz'
xyzfile_name = 'example_extxyz.*' # a serials of files like example_extxyz.1, example_extxyz.2, ...example_extxyz.n
descriptors_path = './descriptors'
descriptor_filename = 'dump_fp' # a serials of dump_fp.* files will be created
der_filename ='dump_der'
# this will create a serials of files for descriptors and their derivatives inside descriptors_path
# by default, descriptor files are saved as 'dump_fp.*' and derivatives are saved as 'dump_der.*'
create_descriptors(xyzfile_path = xyzfile_path, \
xyzfile_name = xyzfile_name, \
lmpexe = lmpexe, \
descriptors_path = descriptors_path, \
descriptor = descriptor, \
descriptor_filename = descriptor_filename, \
der_filename = der_filename)
Start creating fingerprints ...
so far finished for 10 images ...
so far finished for 20 images ...
so far finished for 30 images ...
so far finished for 40 images ...
so far finished for 50 images ...
Finish creating descriptors and their derivatives from total 50 images.
It took 5.02 seconds.
Read inputs&outputs
Read inputs and outputs into a Data object
[4]:
# create a Data object
grdata = Data()
# read inputs: descriptors and their derivatives
fp_filename = descriptors_path + '/dump_fp.*'
der_filename = descriptors_path + '/dump_der.*'
grdata.read_inputdata(fp_filename = fp_filename,der_filename = der_filename)
Reading fingerprints data from LAMMPS dump files ./descriptors/dump_fp.i
so far read 50 images ...
Finish reading fingerprints from total 50 images.
image number = 50
max number of atom = 4
number of fingerprints = 22
type of atoms = 1
Reading derivative data from a series of files ./descriptors/dump_der.i
This may take a while for large data set ...
so far read 50 images ...
Finish reading dGdr derivatives from total 50 images.
Pad zeros to derivatives data if needed ...
Pading finished: 48 images derivatives have been padded with zeros.
image number = 50
max number of derivative pairs = 200
number of fingerprints = 22
It took 0.90 seconds to read the derivatives data.
[5]:
# read outputs: potential energy, force and stress from extxyz files
grdata.read_outputdata(xyzfile_path=xyzfile_path, xyzfile_name=xyzfile_name)
Reading outputs from extxyz files ...
so far read 50 images ...
Finish reading outputs from total 50 images.
Create TFdataset
Create tensorflow dataset for training
[6]:
# convert data to tensors
grdata.convert_data_to_tensor()
Conversion may take a while for large datasets...
It took 0.2547 second.
[8]:
# create tensorflow dataset
tf_dataset = tf.data.Dataset.from_tensor_slices((grdata.input_dict,grdata.output_dict))
dataset_path = './example_tfdataset'
# save the dataset
tf.data.experimental.save(tf_dataset, dataset_path)
# save the element_spec to disk for future loading, this is only needed for tensorflow lower than 2.6
with open(dataset_path + '/element_spec', 'wb') as out_:
pickle.dump(tf_dataset.element_spec, out_)
Note: The above three steps just need to be done once for one data set, the training only uses the saved tensorflow dataset.
Training
Load the dataset and train the model
[9]:
# load tensorflow dataset, for Tensorflow version lower than 2.6, need to specify element_spec.
with open(dataset_path + '/element_spec', 'rb') as in_:
element_spec = pickle.load(in_)
dataset = tf.data.experimental.load(dataset_path,element_spec=element_spec)
[10]:
# split the data to training, validation and testing sets
train_dataset, val_dataset, test_dataset = split_dataset(dataset,0.7,0.2,0.1,shuffle=True)
Traning data: 35 images
Validation data: 10 images
Test data: 5 images
[11]:
# Build the network
# See section 'Training' for detailed description on Network object.
elements = ['C']
act_fun = 'relu' # activation function
nfp = get_fingerprints_num(dataset) # number of fingerprints (or descriptors)
arch = [10,10] # NN layers
model = Network(elements = elements,\
num_fingerprints = nfp,\
arch = arch,\
activation_function = act_fun)
[12]:
# Train the model
opt = 'Adam' # optimizer
loss_fun = 'mae' # loss function
scaling = 'std' # scaling the traning data with standardization
lr = 0.02 # learning rate
loss_weights = {'pe' : 1, 'force' : 1, 'stress': 0.1} # the weights in loss function
model.train(train_dataset, val_dataset, \
optimizer=opt, \
loss_fun = loss_fun, \
batch_size=30, \
lr=lr, \
epochs=50, \
scaling=scaling, \
loss_weights=loss_weights, \
compute_all_loss=True, \
shuffle=True, \
append_loss=True)
Forces are used for training.
Stresses are used for training.
Scaling factors are computed using training dataset.
Training dataset are standardized.
Validation dataset are standardized.
Training dataset will be shuffled during training.
===> Epoch 1/50 - 0.242s/epoch
training_loss - pe_loss: 63.060 - force_loss: 340.074 - stress_loss: 7355.740 - total_loss: 1138.708
validation_loss - pe_loss: 47.981 - force_loss: 340.109 - stress_loss: 11641.806 - total_loss: 1552.271
===> Epoch 2/50 - 0.202s/epoch
training_loss - pe_loss: 41.839 - force_loss: 338.547 - stress_loss: 6488.671 - total_loss: 1029.253
validation_loss - pe_loss: 37.360 - force_loss: 302.898 - stress_loss: 11096.109 - total_loss: 1449.869
===> Epoch 3/50 - 0.229s/epoch
training_loss - pe_loss: 30.148 - force_loss: 295.398 - stress_loss: 6031.364 - total_loss: 928.682
validation_loss - pe_loss: 27.729 - force_loss: 257.073 - stress_loss: 6611.963 - total_loss: 945.998
===> Epoch 4/50 - 0.221s/epoch
training_loss - pe_loss: 25.499 - force_loss: 264.563 - stress_loss: 5426.328 - total_loss: 832.694
validation_loss - pe_loss: 21.732 - force_loss: 222.970 - stress_loss: 4001.949 - total_loss: 644.896
===> Epoch 5/50 - 0.223s/epoch
training_loss - pe_loss: 19.913 - force_loss: 256.813 - stress_loss: 4623.454 - total_loss: 739.071
validation_loss - pe_loss: 18.560 - force_loss: 204.918 - stress_loss: 3570.819 - total_loss: 580.560
===> Epoch 6/50 - 0.216s/epoch
training_loss - pe_loss: 20.351 - force_loss: 214.047 - stress_loss: 4919.543 - total_loss: 726.352
validation_loss - pe_loss: 16.724 - force_loss: 187.974 - stress_loss: 2774.870 - total_loss: 482.185
===> Epoch 7/50 - 0.228s/epoch
training_loss - pe_loss: 16.538 - force_loss: 212.149 - stress_loss: 4363.531 - total_loss: 665.040
validation_loss - pe_loss: 14.973 - force_loss: 169.384 - stress_loss: 2824.495 - total_loss: 466.807
===> Epoch 8/50 - 0.204s/epoch
training_loss - pe_loss: 11.135 - force_loss: 173.746 - stress_loss: 3679.028 - total_loss: 552.783
validation_loss - pe_loss: 14.269 - force_loss: 155.110 - stress_loss: 2688.537 - total_loss: 438.233
===> Epoch 9/50 - 0.217s/epoch
training_loss - pe_loss: 13.449 - force_loss: 152.360 - stress_loss: 3108.144 - total_loss: 476.624
validation_loss - pe_loss: 14.968 - force_loss: 141.976 - stress_loss: 3357.161 - total_loss: 492.661
===> Epoch 10/50 - 0.205s/epoch
training_loss - pe_loss: 17.161 - force_loss: 144.477 - stress_loss: 3740.302 - total_loss: 535.668
validation_loss - pe_loss: 16.087 - force_loss: 129.152 - stress_loss: 3363.140 - total_loss: 481.553
===> Epoch 11/50 - 0.211s/epoch
training_loss - pe_loss: 17.185 - force_loss: 121.094 - stress_loss: 3050.336 - total_loss: 443.312
validation_loss - pe_loss: 17.087 - force_loss: 113.933 - stress_loss: 2551.663 - total_loss: 386.186
===> Epoch 12/50 - 0.224s/epoch
training_loss - pe_loss: 16.637 - force_loss: 109.219 - stress_loss: 2370.110 - total_loss: 362.866
validation_loss - pe_loss: 17.689 - force_loss: 97.074 - stress_loss: 2602.237 - total_loss: 374.987
===> Epoch 13/50 - 0.217s/epoch
training_loss - pe_loss: 16.613 - force_loss: 105.366 - stress_loss: 2287.128 - total_loss: 350.692
validation_loss - pe_loss: 17.418 - force_loss: 91.997 - stress_loss: 2337.202 - total_loss: 343.135
===> Epoch 14/50 - 0.215s/epoch
training_loss - pe_loss: 19.297 - force_loss: 87.292 - stress_loss: 1404.290 - total_loss: 247.018
validation_loss - pe_loss: 16.794 - force_loss: 88.163 - stress_loss: 2260.646 - total_loss: 331.022
===> Epoch 15/50 - 0.190s/epoch
training_loss - pe_loss: 16.452 - force_loss: 93.070 - stress_loss: 1363.711 - total_loss: 245.893
validation_loss - pe_loss: 16.137 - force_loss: 82.981 - stress_loss: 2126.521 - total_loss: 311.770
===> Epoch 16/50 - 0.193s/epoch
training_loss - pe_loss: 16.693 - force_loss: 79.436 - stress_loss: 1505.886 - total_loss: 246.717
validation_loss - pe_loss: 15.632 - force_loss: 78.440 - stress_loss: 1899.606 - total_loss: 284.033
===> Epoch 17/50 - 0.203s/epoch
training_loss - pe_loss: 16.359 - force_loss: 84.692 - stress_loss: 1567.637 - total_loss: 257.815
validation_loss - pe_loss: 15.098 - force_loss: 72.142 - stress_loss: 1882.750 - total_loss: 275.515
===> Epoch 18/50 - 0.247s/epoch
training_loss - pe_loss: 17.538 - force_loss: 70.511 - stress_loss: 1223.243 - total_loss: 210.374
validation_loss - pe_loss: 14.630 - force_loss: 67.023 - stress_loss: 2512.499 - total_loss: 332.903
===> Epoch 19/50 - 0.191s/epoch
training_loss - pe_loss: 14.991 - force_loss: 68.985 - stress_loss: 1350.129 - total_loss: 218.989
validation_loss - pe_loss: 14.003 - force_loss: 63.077 - stress_loss: 2543.449 - total_loss: 331.425
===> Epoch 20/50 - 0.200s/epoch
training_loss - pe_loss: 15.257 - force_loss: 59.828 - stress_loss: 1157.593 - total_loss: 190.844
validation_loss - pe_loss: 13.590 - force_loss: 59.145 - stress_loss: 2209.569 - total_loss: 293.691
===> Epoch 21/50 - 0.228s/epoch
training_loss - pe_loss: 13.402 - force_loss: 67.119 - stress_loss: 1015.503 - total_loss: 182.071
validation_loss - pe_loss: 13.357 - force_loss: 53.518 - stress_loss: 1958.299 - total_loss: 262.704
===> Epoch 22/50 - 0.193s/epoch
training_loss - pe_loss: 13.518 - force_loss: 56.822 - stress_loss: 839.241 - total_loss: 154.264
validation_loss - pe_loss: 13.425 - force_loss: 48.992 - stress_loss: 1616.169 - total_loss: 224.034
===> Epoch 23/50 - 0.253s/epoch
training_loss - pe_loss: 13.768 - force_loss: 56.009 - stress_loss: 877.928 - total_loss: 157.570
validation_loss - pe_loss: 13.435 - force_loss: 48.059 - stress_loss: 1219.728 - total_loss: 183.467
===> Epoch 24/50 - 0.231s/epoch
training_loss - pe_loss: 13.434 - force_loss: 58.265 - stress_loss: 1123.461 - total_loss: 184.045
validation_loss - pe_loss: 13.149 - force_loss: 42.599 - stress_loss: 1004.809 - total_loss: 156.228
===> Epoch 25/50 - 0.207s/epoch
training_loss - pe_loss: 11.494 - force_loss: 49.842 - stress_loss: 948.868 - total_loss: 156.223
validation_loss - pe_loss: 13.072 - force_loss: 36.523 - stress_loss: 985.632 - total_loss: 148.158
===> Epoch 26/50 - 0.217s/epoch
training_loss - pe_loss: 13.035 - force_loss: 46.092 - stress_loss: 821.157 - total_loss: 141.243
validation_loss - pe_loss: 13.018 - force_loss: 34.420 - stress_loss: 879.450 - total_loss: 135.384
===> Epoch 27/50 - 0.199s/epoch
training_loss - pe_loss: 14.402 - force_loss: 39.259 - stress_loss: 422.067 - total_loss: 95.868
validation_loss - pe_loss: 12.979 - force_loss: 32.963 - stress_loss: 743.509 - total_loss: 120.293
===> Epoch 28/50 - 0.207s/epoch
training_loss - pe_loss: 13.238 - force_loss: 41.517 - stress_loss: 430.548 - total_loss: 97.810
validation_loss - pe_loss: 12.728 - force_loss: 29.243 - stress_loss: 581.828 - total_loss: 100.154
===> Epoch 29/50 - 0.205s/epoch
training_loss - pe_loss: 12.872 - force_loss: 36.499 - stress_loss: 506.248 - total_loss: 99.996
validation_loss - pe_loss: 12.348 - force_loss: 27.912 - stress_loss: 696.936 - total_loss: 109.954
===> Epoch 30/50 - 0.232s/epoch
training_loss - pe_loss: 12.664 - force_loss: 44.302 - stress_loss: 485.721 - total_loss: 105.538
validation_loss - pe_loss: 12.160 - force_loss: 28.085 - stress_loss: 690.873 - total_loss: 109.333
===> Epoch 31/50 - 0.224s/epoch
training_loss - pe_loss: 12.688 - force_loss: 35.669 - stress_loss: 385.926 - total_loss: 86.950
validation_loss - pe_loss: 12.399 - force_loss: 26.697 - stress_loss: 563.213 - total_loss: 95.418
===> Epoch 32/50 - 0.210s/epoch
training_loss - pe_loss: 12.791 - force_loss: 30.050 - stress_loss: 371.575 - total_loss: 79.998
validation_loss - pe_loss: 12.590 - force_loss: 26.551 - stress_loss: 511.294 - total_loss: 90.270
===> Epoch 33/50 - 0.238s/epoch
training_loss - pe_loss: 13.013 - force_loss: 33.084 - stress_loss: 518.474 - total_loss: 97.944
validation_loss - pe_loss: 12.531 - force_loss: 26.636 - stress_loss: 437.782 - total_loss: 82.945
===> Epoch 34/50 - 0.175s/epoch
training_loss - pe_loss: 12.870 - force_loss: 27.200 - stress_loss: 465.778 - total_loss: 86.648
validation_loss - pe_loss: 12.371 - force_loss: 26.732 - stress_loss: 472.396 - total_loss: 86.342
===> Epoch 35/50 - 0.230s/epoch
training_loss - pe_loss: 13.072 - force_loss: 28.979 - stress_loss: 457.129 - total_loss: 87.764
validation_loss - pe_loss: 12.162 - force_loss: 27.584 - stress_loss: 405.666 - total_loss: 80.313
===> Epoch 36/50 - 0.177s/epoch
training_loss - pe_loss: 12.871 - force_loss: 28.323 - stress_loss: 359.149 - total_loss: 77.109
validation_loss - pe_loss: 11.897 - force_loss: 25.966 - stress_loss: 308.571 - total_loss: 68.720
===> Epoch 37/50 - 0.216s/epoch
training_loss - pe_loss: 12.214 - force_loss: 30.554 - stress_loss: 343.573 - total_loss: 77.126
validation_loss - pe_loss: 11.583 - force_loss: 27.246 - stress_loss: 341.293 - total_loss: 72.958
===> Epoch 38/50 - 0.205s/epoch
training_loss - pe_loss: 11.326 - force_loss: 27.573 - stress_loss: 374.659 - total_loss: 76.365
validation_loss - pe_loss: 10.775 - force_loss: 27.324 - stress_loss: 264.535 - total_loss: 64.553
===> Epoch 39/50 - 0.225s/epoch
training_loss - pe_loss: 10.716 - force_loss: 25.122 - stress_loss: 391.479 - total_loss: 74.985
validation_loss - pe_loss: 9.601 - force_loss: 25.424 - stress_loss: 377.649 - total_loss: 72.790
===> Epoch 40/50 - 0.196s/epoch
training_loss - pe_loss: 9.577 - force_loss: 25.639 - stress_loss: 416.391 - total_loss: 76.855
validation_loss - pe_loss: 8.494 - force_loss: 26.807 - stress_loss: 416.565 - total_loss: 76.958
===> Epoch 41/50 - 0.198s/epoch
training_loss - pe_loss: 8.368 - force_loss: 23.657 - stress_loss: 287.868 - total_loss: 60.812
validation_loss - pe_loss: 7.708 - force_loss: 26.754 - stress_loss: 422.066 - total_loss: 76.668
===> Epoch 42/50 - 0.230s/epoch
training_loss - pe_loss: 8.452 - force_loss: 24.731 - stress_loss: 315.003 - total_loss: 64.683
validation_loss - pe_loss: 7.105 - force_loss: 28.294 - stress_loss: 299.194 - total_loss: 65.318
===> Epoch 43/50 - 0.229s/epoch
training_loss - pe_loss: 8.083 - force_loss: 24.970 - stress_loss: 254.668 - total_loss: 58.519
validation_loss - pe_loss: 6.269 - force_loss: 28.521 - stress_loss: 253.969 - total_loss: 60.187
===> Epoch 44/50 - 0.183s/epoch
training_loss - pe_loss: 6.112 - force_loss: 23.348 - stress_loss: 235.360 - total_loss: 52.995
validation_loss - pe_loss: 5.358 - force_loss: 29.082 - stress_loss: 208.927 - total_loss: 55.332
===> Epoch 45/50 - 0.226s/epoch
training_loss - pe_loss: 6.441 - force_loss: 26.129 - stress_loss: 156.721 - total_loss: 48.242
validation_loss - pe_loss: 4.450 - force_loss: 28.374 - stress_loss: 186.346 - total_loss: 51.459
===> Epoch 46/50 - 0.221s/epoch
training_loss - pe_loss: 4.000 - force_loss: 23.461 - stress_loss: 151.348 - total_loss: 42.597
validation_loss - pe_loss: 3.738 - force_loss: 27.473 - stress_loss: 168.654 - total_loss: 48.076
===> Epoch 47/50 - 0.185s/epoch
training_loss - pe_loss: 4.507 - force_loss: 23.344 - stress_loss: 174.907 - total_loss: 45.341
validation_loss - pe_loss: 3.287 - force_loss: 27.115 - stress_loss: 141.923 - total_loss: 44.594
===> Epoch 48/50 - 0.183s/epoch
training_loss - pe_loss: 3.173 - force_loss: 24.408 - stress_loss: 139.998 - total_loss: 41.581
validation_loss - pe_loss: 2.883 - force_loss: 26.482 - stress_loss: 162.336 - total_loss: 45.598
===> Epoch 49/50 - 0.231s/epoch
training_loss - pe_loss: 3.309 - force_loss: 21.386 - stress_loss: 93.648 - total_loss: 34.059
validation_loss - pe_loss: 2.527 - force_loss: 24.680 - stress_loss: 203.034 - total_loss: 47.511
===> Epoch 50/50 - 0.209s/epoch
training_loss - pe_loss: 2.896 - force_loss: 23.390 - stress_loss: 137.304 - total_loss: 40.017
validation_loss - pe_loss: 2.308 - force_loss: 23.773 - stress_loss: 195.185 - total_loss: 45.600
End of training, elapsed time: 00:00:10
[13]:
# plot the training loss
model.plot_loss(start_epoch=1)
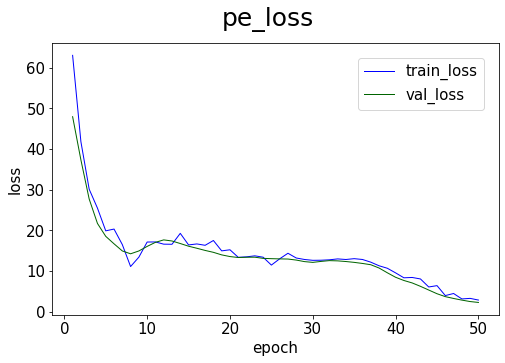
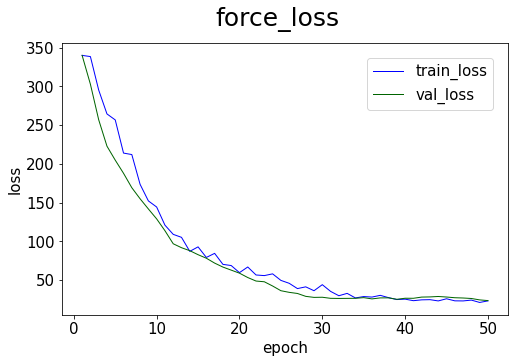
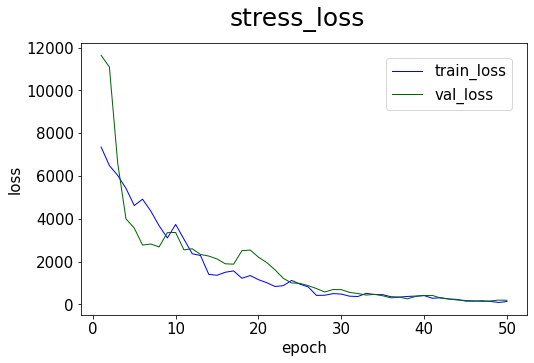
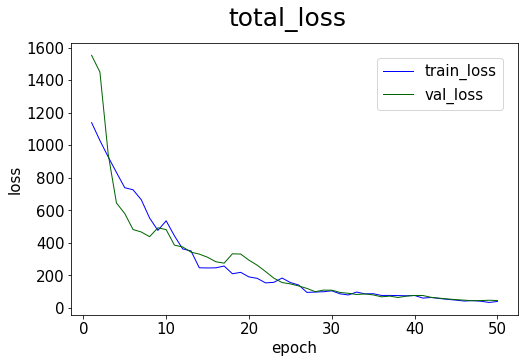
[14]:
# Evaluate using the first 5 data in test dataset
model.evaluate(test_dataset.take(5),return_prediction=False)
Evaluation loss is:
pe_loss: 1.5027e+00
force_loss: 3.3879e+01
stress_loss: 2.5975e+02
total_loss: 6.1357e+01
The total loss is computed using the loss weights - pe: 1.00 - force: 1.00 - stress: 0.10
[15]:
# prediction using the first 5 data in test dataset
input_dict = get_input_dict(test_dataset.take(5))
model.predict(input_dict)
[15]:
{'pe': array([-24.43516537, -27.25794917, -26.44558567, -29.71721262,
-26.18328476]),
'force': array([[[-14.98369464, 60.16402837, -11.24057251],
[ 27.58750673, -46.4019775 , 11.68806955],
[ 50.03849536, 47.02174987, -46.65503074],
[-62.64230727, -60.78380053, 46.2075337 ]],
[[ 66.39126588, -0.918724 , 31.74912699],
[ 2.26208116, 17.5541579 , -31.09016267],
[-42.02774142, 45.56440882, -12.25110425],
[-26.62560584, -62.19984267, 11.59213992]],
[[-70.52058765, 80.59492525, -15.88633072],
[ 95.63537577, -90.82699739, 12.29866236],
[ 40.98061171, -82.91953395, 15.95529539],
[-66.09539983, 93.15160611, -12.36762705]],
[[ 35.92992587, -28.45139903, 43.08669821],
[-42.52183304, 13.74105695, -30.8883209 ],
[ 28.8808097 , 16.15299698, 12.92609446],
[-22.28890239, -1.4426549 , -25.12447177]],
[[ 10.62635586, -23.71130926, 3.13159382],
[-24.0703802 , 40.75223825, 3.90257854],
[ -6.31185408, -37.11107881, 26.76910415],
[ 19.75587847, 20.07014987, -33.80327653]]]),
'stress': array([[-4.74467792e+02, 4.50541291e+01, 7.48435275e-01,
4.50541293e+01, -4.45066829e+02, -1.39581531e+00,
7.48433858e-01, -1.39581685e+00, 8.08017409e-01],
[ 1.46181081e+03, 3.81848270e+01, -3.52670752e+00,
3.81848270e+01, 1.34280176e+03, 4.23490518e+00,
-3.52670589e+00, 4.23490481e+00, -1.47902890e+00],
[-1.00130692e+03, -1.73574190e+01, 3.24464109e+00,
-1.73574189e+01, -1.03593198e+03, -3.93371377e+00,
3.24464110e+00, -3.93371389e+00, 5.60459398e-01],
[-6.92777205e+02, -3.50395507e+01, 3.72795564e-01,
-3.50395507e+01, -6.08529653e+02, -4.44634887e-01,
3.72794506e-01, -4.44634859e-01, 6.23967448e-01],
[ 9.13840620e+01, -5.63079683e+01, -4.92513182e-01,
-5.63079682e+01, 4.23616309e+02, 9.50404198e-01,
-4.92513625e-01, 9.50403883e-01, -5.03840202e-02]])}
Save/load model
save the trained model
[17]:
# we re-write the descriptor here to empasize that it should be the same one defined above
descriptor = {'name': 'acsf',
'cutoff': 6.5,
'etaG2':[0.01,0.05,0.1,0.5,1,5,10],
'etaG4': [0.01],
'zeta': [0.08,0.2,1.0,5.0,10.0,50.0,100.0],
'lambda': [1.0, -1.0]}
save_dir = 'example.tfdnn'
network.save(model,save_dir,descriptor=descriptor)
INFO:tensorflow:Assets written to: example.tfdnn/assets
Network signatures and descriptor are written to example.tfdnn/parameters for LAMMPS simulation.
Load the trained model for continuous training and prediction
[18]:
imported_model = network.load(save_dir)
# Re-train the model
loss_weights = {'pe' : 1, 'force' : 1, 'stress': 0.1}
opt = 'Adam'
loss_fun = 'rmse'
scaling = 'std'
model.train(train_dataset, val_dataset, \
optimizer=opt, \
loss_fun = loss_fun, \
batch_size=30, \
lr=0.02, \
epochs=5, \
scaling=scaling, \
loss_weights=loss_weights, \
compute_all_loss=True, \
shuffle=True, \
append_loss=True)
Network has been inflated! self.built: True
Forces are used for training.
Stresses are used for training.
Scaling factors are computed using training dataset.
Training dataset are standardized.
Validation dataset are standardized.
Training dataset will be shuffled during training.
===> Epoch 1/5 - 0.209s/epoch
training_loss - pe_loss: 3.176 - force_loss: 25.337 - stress_loss: 287.488 - total_loss: 57.262
validation_loss - pe_loss: 4.905 - force_loss: 25.092 - stress_loss: 710.237 - total_loss: 101.021
===> Epoch 2/5 - 0.182s/epoch
training_loss - pe_loss: 4.932 - force_loss: 24.058 - stress_loss: 421.647 - total_loss: 71.155
validation_loss - pe_loss: 5.630 - force_loss: 22.020 - stress_loss: 581.018 - total_loss: 85.751
===> Epoch 3/5 - 0.214s/epoch
training_loss - pe_loss: 5.663 - force_loss: 20.711 - stress_loss: 462.624 - total_loss: 72.636
validation_loss - pe_loss: 7.609 - force_loss: 21.834 - stress_loss: 472.273 - total_loss: 76.671
===> Epoch 4/5 - 0.204s/epoch
training_loss - pe_loss: 7.579 - force_loss: 18.940 - stress_loss: 349.679 - total_loss: 61.486
validation_loss - pe_loss: 9.569 - force_loss: 19.086 - stress_loss: 308.439 - total_loss: 59.499
===> Epoch 5/5 - 0.196s/epoch
training_loss - pe_loss: 8.719 - force_loss: 20.088 - stress_loss: 184.540 - total_loss: 47.261
validation_loss - pe_loss: 9.957 - force_loss: 19.737 - stress_loss: 293.991 - total_loss: 59.094
End of training, elapsed time: 00:00:01
[19]:
imported_model.evaluate(test_dataset.take(5),return_prediction=False)
Evaluation loss is:
pe_loss: 1.5027e+00
force_loss: 3.3879e+01
stress_loss: 2.5975e+02
total_loss: 6.1357e+01
The total loss is computed using the loss weights - pe: 1.00 - force: 1.00 - stress: 0.10
[20]:
input_dict = get_input_dict(test_dataset.take(5))
imported_model.predict(input_dict)
[20]:
{'pe': array([-24.43516537, -27.25794917, -26.44558567, -29.71721262,
-26.18328476]),
'force': array([[[-14.98369464, 60.16402837, -11.24057251],
[ 27.58750673, -46.4019775 , 11.68806955],
[ 50.03849536, 47.02174987, -46.65503074],
[-62.64230727, -60.78380053, 46.2075337 ]],
[[ 66.39126588, -0.918724 , 31.74912699],
[ 2.26208116, 17.5541579 , -31.09016267],
[-42.02774142, 45.56440882, -12.25110425],
[-26.62560584, -62.19984267, 11.59213992]],
[[-70.52058765, 80.59492525, -15.88633072],
[ 95.63537577, -90.82699739, 12.29866236],
[ 40.98061171, -82.91953395, 15.95529539],
[-66.09539983, 93.15160611, -12.36762705]],
[[ 35.92992587, -28.45139903, 43.08669821],
[-42.52183304, 13.74105695, -30.8883209 ],
[ 28.8808097 , 16.15299698, 12.92609446],
[-22.28890239, -1.4426549 , -25.12447177]],
[[ 10.62635586, -23.71130926, 3.13159382],
[-24.0703802 , 40.75223825, 3.90257854],
[ -6.31185408, -37.11107881, 26.76910415],
[ 19.75587847, 20.07014987, -33.80327653]]]),
'stress': array([[-4.74467792e+02, 4.50541291e+01, 7.48435275e-01,
4.50541293e+01, -4.45066829e+02, -1.39581531e+00,
7.48433858e-01, -1.39581685e+00, 8.08017409e-01],
[ 1.46181081e+03, 3.81848270e+01, -3.52670752e+00,
3.81848270e+01, 1.34280176e+03, 4.23490518e+00,
-3.52670589e+00, 4.23490481e+00, -1.47902890e+00],
[-1.00130692e+03, -1.73574190e+01, 3.24464109e+00,
-1.73574189e+01, -1.03593198e+03, -3.93371377e+00,
3.24464110e+00, -3.93371389e+00, 5.60459398e-01],
[-6.92777205e+02, -3.50395507e+01, 3.72795564e-01,
-3.50395507e+01, -6.08529653e+02, -4.44634887e-01,
3.72794506e-01, -4.44634859e-01, 6.23967448e-01],
[ 9.13840620e+01, -5.63079683e+01, -4.92513182e-01,
-5.63079682e+01, 4.23616309e+02, 9.50404198e-01,
-4.92513625e-01, 9.50403883e-01, -5.03840202e-02]])}